Layout analysis
Find page-level staff regions and structural guide lines before staff-local recognition.


FindLab Starry
FindLab
We propose a new approach for a practical two-stage Optical Music Recognition (OMR) pipeline, with a particular focus on its second stage. Given symbol and event candidates from the visual pipeline, we decode them into an editable, verifiable, and exportable score structure. We focus on complex polyphonic staff notation, especially piano scores, where voice separation and intra-measure timing are the main bottlenecks. Our approach formulates second-stage decoding as a structure decoding problem and uses topology recognition with probability-guided search (BeadSolver) as its core method. We also describe a data strategy that combines procedural generation with recognition-feedback annotations. The result is a practical decoding component for real OMR systems and a path to accumulate structured score data for future end-to-end, multimodal, and RL-style methods.
In complex piano notation, the main bottleneck is often not detecting individual noteheads, stems, or rests, but deciding how locally plausible events should be assembled into voices and timing. Several voices may overlap at nearly the same horizontal position, partial voices may appear only locally, and rhythmic logic can depend on tuplets, grace notes, or whole-measure rest conventions.

Starry treats OMR as a staged transformation from images to editable music structure. The visual system operates at per-page and per-staff levels to produce event candidates, and regulation resolves measure-level topology into a serialized representation that can be exported to standard music-language formats such as MusicXML and LilyPond.


Find page-level staff regions and structural guide lines before staff-local recognition.
Estimate staff distortion, then render a
rectified staff crop for downstream predictors.



Predict notation-class heatmaps that become local evidence for candidate assembly.

Separate notation foreground from the corrected staff image before symbol grouping.

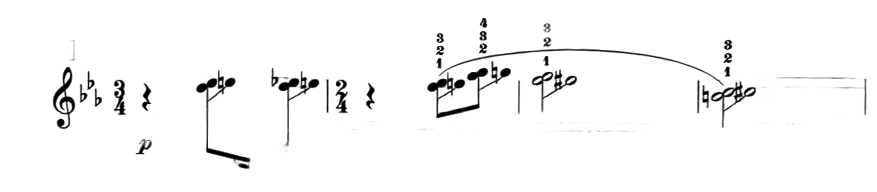
Recognize staff grouping marks at the left edge of a system and serialize them as structural tokens.


BeadSolver treats measure-level decoding as a topology problem. Instead of asking the system to predict a complete polyphonic structure in one shot, it uses probability-guided tree search to explore candidate voice-chain assignments among event candidates, then selects a topology that becomes globally coherent in time.

The key idea is to separate local evidence from structural commitment. The model estimates which continuation is plausible at each step, while the solver keeps multiple possibilities alive long enough to compare their consequences at the measure level.


How can structure decoding across multiple voices be formulated as a Markov decision process? One useful intuition is to treat each barline as a space-time portal: the solver may finish one voice, jump through the barline, and continue from the beginning of another voice, while keeping the global measure structure consistent.

The following examples visualize how different solvers explore measure-level topology candidates and converge to coherent voice structures. Click a image to play animation.
BeadPicker is the learned model inside the solver. At each step, it reads the current measure candidates together with the committed prefix, then estimates a probability distribution over which event should come next, including voice-closing boundary markers, and provides duration predispositions and tick estimates used by the evaluator.

The examples below show a simplified player for Starry recognition results. You can play back the preview output and switch between the original score image and the segmented, denoised view to compare the two visualizations.
Try the live demo on Hugging Face: upload a score image or PDF for Starry recognition, inspect and edit the recognized result, and export it to MusicXML and other standard music notation formats.